Got Criminal Ancestors? How to Investigate Their Crimes
Lydia thinks her great-grandfather was murdered–perhaps even by her grandfather! Here’s some advice for her and everyone researching “cold cases” for criminal ancestors on your family tree.

I heard recently from Lydia with these intriguing questions:
My great great grandpa William John Gabriel Nelson disappeared one day, never coming home from work. It was family lore that he had been “shanghai’d.” But even as a child the story didn’t add up. [Through a] few other mentions of the account throughout the years, and recently reconnecting with cousins through Ancestry.com/DNA and your advice to just email DNA matches, I have a growing reason to believe my great-grandfather was murdered. An even bigger fear is that my grandfather may have been the one to do it.All parties involved with this are now dead, so follow-up is impossible with them. But I’m wondering about contacting the Los Angeles Police Department (LAPD) or the library to determine if indeed there was a cold case, missing persons report or John Doe. Since this happened in the mid 1940’s, would I contact the LAPD or is this now a job for a historian?
As a citizen, Lydia can certainly contact the LAPD here. It might take a bit of persistence to get to the right person or resource. I would start by asking for how you can find out the status of a cold case from the year in question.
Here are 4 ways to follow up on your own criminal ancestors’ cold cases:
1. Look for cold case files online.
As I often say, all good searches start online because they will help you prepare to go offline. In other words, not everything is online, but searching online first will give you a lay of the land, revealing what is available, who to contact, and where to go in person. Start with a Google search such as LAPD cold cases. The search results include several good leads:
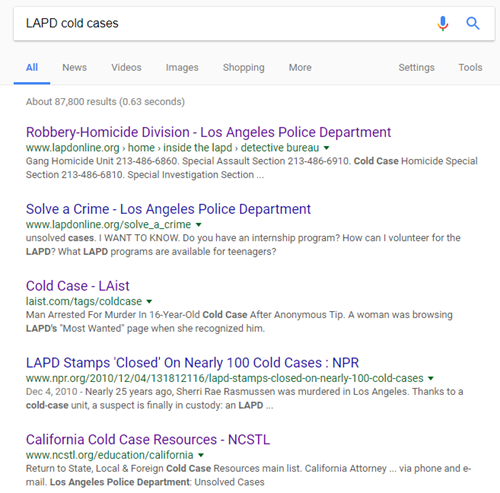
With a case like Lydia’s that is over 70 years old, I wouldn’t expect to pull it up in an online database (though you never know!) But I do see several sites here that provide phone numbers to gain access to those who can lead you in the right direction.
2. Search Google for clues.
 Use Google’s powerful search technology to look for online mentions of the names, places, and dates of your particular case.
Use Google’s powerful search technology to look for online mentions of the names, places, and dates of your particular case.
In Lydia’s case, she might begin with keywords relating to her great-grandfather’s disappearance, with his name, year, and the place he was last seen. Including descriptive keywords such as disappear, mystery, vanished or murder might also yield helpful results.
Learn more about effective search techniques in my book, The Genealogist’s Google Toolbox, Second Edition.
3. Check old newspapers.
Newspapers in your ancestor’s hometown (or further afield) may have mentioned the incident. With a common name like William (or Bill) Nelson, you may need to weed out the overabundance of unwanted results you get. Let me show you how I did this in GenealogyBank, a popular genealogical newspaper website:
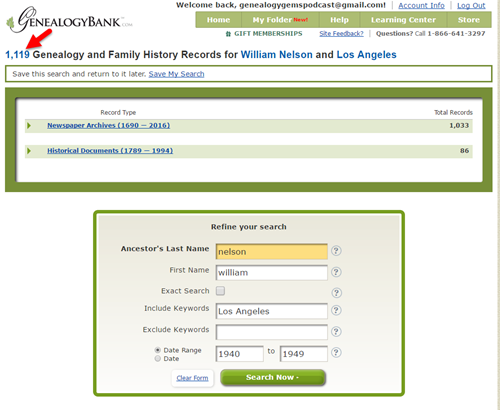
The initial results of searching GenealogyBank (above) for the terms William Nelson and Los Angeles brought up over 1,000 search results! (The red arrow points to the tally.) Since I don’t like wasting valuable research time on irrelevant results (who’s with me?!), I refined the search. I specified Nelson as a last name, William as a first name, Los Angeles as a keyword, and I added a date range: the decade during which he disappeared. Next, I limited my search to Los Angeles-area newspapers, shown below:
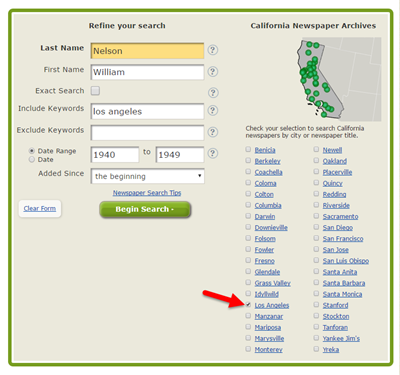
This search narrows results down to under 200: a robust number, but at least manageable to look through for relevant material.
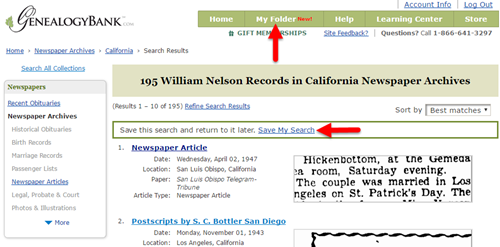
I want to be able to use these same search parameters in the future, so I click Save My Search. The search now appears in My Folder for future reference.
4. Look for criminal records.
 If you knew (or suspected) that a relative was prosecuted for a crime, it’s time to start looking for records relating to the criminal case. There may be several kinds:
If you knew (or suspected) that a relative was prosecuted for a crime, it’s time to start looking for records relating to the criminal case. There may be several kinds:
- In cases of suspicious death (where there was a body, unlike Lydia’s case), look for any surviving coroner’s records.
- If a trial may have occurred, research the jurisdiction to find out what court would have handled it, and then look for files relating to the case.
- If an ancestor may have served time, look for prison records. Genealogy Gems Premium podcast episode 29 is devoted to the topic of prison records.
Get inspired!
Read this article about a woman who was researching not one but two mysterious deaths on her family tree.
Want to help investigators lay to rest their own cold cases?
Click here to read about the Unclaimed Persons Project and how you can help.
